IDEA快捷键:
F2 显示document
alt(左) +entry 快速修复
ctrl +shift +p(alt +shift +z) Surround With...
alt +shift +s Generator
ctrl +alt +v 快速补齐Variable
ctrl +shift +t 查找某个类或者方法
ctrl +o 列举当前文件的类和方法,还可以快速选择重写方法
ctrl +h 打开所选类中继承关系(可做全局搜索)
ctrl +alt +/ (显示可输入变量?)
alt +左/右方向键 返回/前进上一个查看的位置
alt(左) + 上/下方向键 把当前行换到上/下一行
alt(左) + 上/下方向键 把当前行复制到上/下行
alt + 光标选择 一次选多行
alt + 7 打开一个列表显示类和方法
shitf + shift 按java类,全局搜索
ctrl +h 按照路径全局搜索
对象
对象 实例 类的关联:
Person p = new Person();
p是对象,new Person()则是通过类创建的实例,对象p指向实例new Person()。
- 运行时类
是Class类的实例,每个class进入内存时都会创建一个对应的Class类的实例,也就是运行时类
Class clazz1 = Person.class;
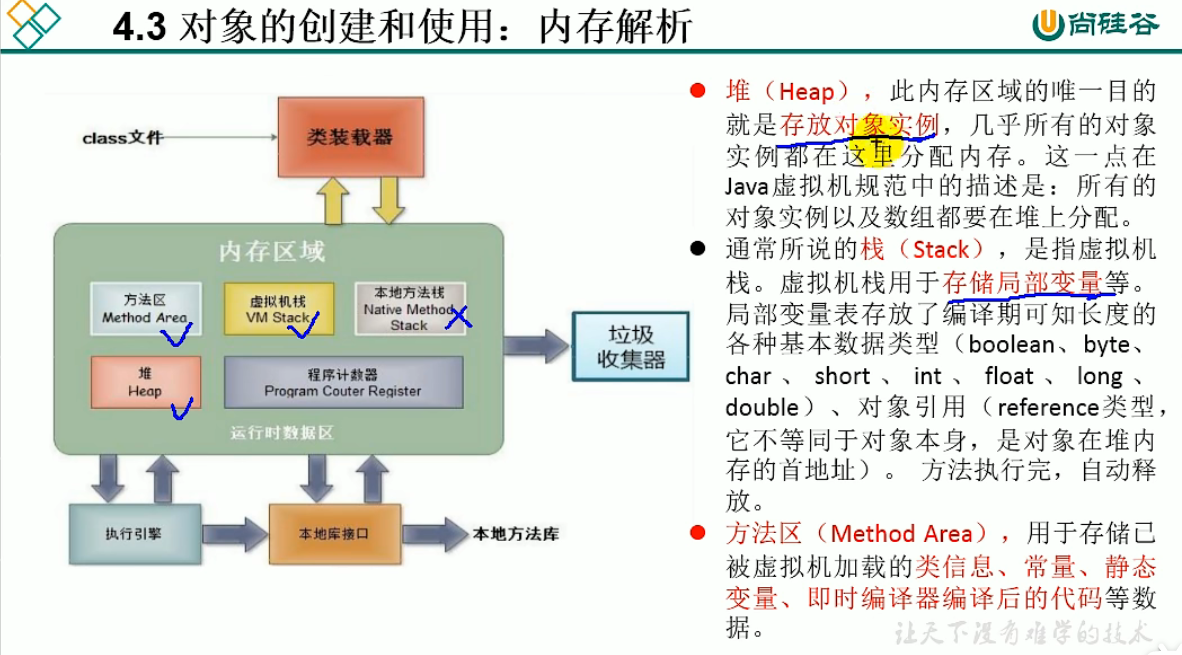
1.内存:
可变性参数要写在形参的末尾
// * 1.jdk 5.0新增的内容
// * 2.具体使用:
// * 2.1 可变个数形参的格式:数据类型 ... 变量名
// * 2.2 当调用可变个数形参的方法时,传入的参数个数可以是:0个,1个,2个,。。。
// * 2.3 可变个数形参的方法与本类中方法名相同,形参不同的方法之间构成重载
// * 2.4 可变个数形参的方法与本类中方法名相同,形参类型也相同的数组之间不构成重载。换句话说,二者不能共存。
// * 2.5 可变个数形参在方法的形参中,必须声明在末尾
// * 2.6 可变个数形参在方法的形参中,最多只能声明一个可变形参。
public void show(String ... strs){
System.out.println("show(String ... strs)");
2.类中运行顺序
- ①默认初始化
- ②显式初始化/⑤在代码块中赋值
- ③构造器中初始化
- ④有了对象以后,可以通过"对象.属性"或"对象.方法"的方式,进行赋值
- 执行的先后顺序:① - ② / ⑤ - ③ - ④
代码块: 每次创建对象的时候,都会执行一次。且先于构造器执行。
Integer
https://www.cnblogs.com/lawt/p/14089318.html
Integer m = 1;
Integer n = 1;
System.out.println(m == n);//True
Integer m = 128;
Integer n = 128;
System.out.println(m == n);//False
System.out.println(m.equals(n));//True为了加快内存的响应,当Integer类(不是基本类型int)在默认-128~127的时候,IntegerCache中使用了一个char数组cash[]来映射这些值,数组cash中每个位置都是一个Integer类。不在这个范围中,就会创建一个new Integer新对象。
接口
JDK7及以前:只能定义全局常量和抽象方法
全局常量:public static final的.但是书写时,可以省略不写
抽象方法:public abstract的- JDK8:除了定义全局常量和抽象方法之外,还可以定义静态方法、默认方法
- 当子类继承的父类和实现的接口中声明了同名的参数默认方法,子类在没有重写的情况下默认调用父类方法。
- 接口中默认方法的使用:接口名.super.默认方法名()
String
1. String中的char[]都是final的
2. final String
String s1 = "javaEEhadoop";
String s2 = "javaEE";
String s3 = s2 + "hadoop";
System.out.println(s1 == s3);//false
final String s4 = "javaEE";//s4:常量
String s5 = s4 + "hadoop";
System.out.println(s1 == s5);//truefinal修饰的String在相加的时候等同于字符串直接相加:
final a = "a",
final b = "b";
a+b == "a"+"b" == "ab"
因为+号两边都是常量,其值在编译期就可以确定,由于编译器优化,在编译期就将+两边拼接合并了,直接合并成是一个常量"ab"。
但是如果把final去掉,a+b == "a" + "b" 就是false了,因为不用final修饰,a和b都是对象,在编译期无法确定其值,所以要等到运行期再进行处理,处理方法:先new一个StringBuilder,然后append a和 b,最后相加的结果是一个堆中new出来的一个对象
3. 与各个类型之间的转换
与基本数据类型、包装类之间的转换
String --> 基本数据类型、包装类:调用包装类的静态方法:parseXxx(str)
基本数据类型、包装类 --> String:调用String重载的valueOf(xxx)
与字符串数组
String --> char[]:调用String的toCharArray()
char[] --> String:调用String的构造器(String(char[]))
与字节数组
编码:String --> byte[]:调用String的getBytes()
解码:byte[] --> String:调用String的构造器(String(byte[]))
与StringBuffer、StringBuilder之间的转换
String -->StringBuffer、StringBuilder:调用StringBuffer、StringBuilder构造器
StringBuffer、StringBuilder -->String:①调用String构造器;②StringBuffer、StringBuilder的toString()
4. StringBuffer
可变的字符序列;线程安全的,效率低;底层使用char[]存储
StringBuffer sb1 = new StringBuffer();//char[] value = new char[16];底层创建了一个长度是16的数组。
默认情况下,扩容为原来容量的2倍 + 2,同时将原数组中的元素复制到新的数组中。
5. StringBuilder
可变的字符序列;jdk5.0新增的,线程不安全的,效率高;底层使用char[]存储
6. StringBuffer、StringBuilder中的常用方法
增:append(xxx)
删:delete(int start,int end)
改:setCharAt(int n ,char ch) / replace(int start, int end, String str)
查:charAt(int n )
插:insert(int offset, xxx)
长度:length();
遍历:for() + charAt() / toString()
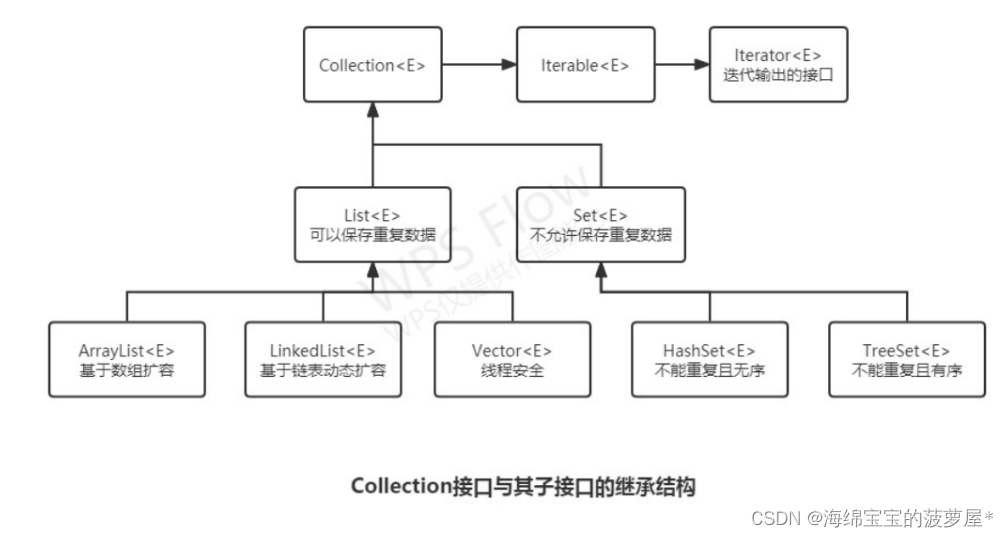
单列集合框架 Collection
https://blog.csdn.net/qq_45687780/article/details/124406490
1. 集合和数组间的互换:
//数组 --->集合
Collection collTemp = Arrays.asList(new String[]{"AA", "BB", "CC"});
//asList中返回的是Arrays.ArrayList,不是java.util.ArrayList,很多方法都没重写
Collection coll = ArrayList(coll);
Iterator iterator = coll.iterator();
//hasNext():判断是否还下一个元素
while(iterator.hasNext()){
//next():①指针下移 ②将下移以后集合位置上的元素返回
System.out.println(iterator.next());
}
//集合 --->数组:toArray()
Object[] arr = coll.toArray();
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}2. 常用实现类
|----Collection接口:单列集合,用来存储一个一个的对象
|----List接口:存储序的、可重复的数据。 -->“动态”数组,替换原的数组
- |----ArrayList:作为List接口的主要实现类;线程不安全的,效率高;底层使用Object[] elementData存储
- |----LinkedList:对于频繁的插入、删除操作,使用此类效率比ArrayList高;底层使用双向链表存储
- |----Vector:作为List接口的古老实现类;线程安全的,效率低;底层使用Object[] elementData存储
|----Set接口:存储无序的、不可重复的数据 -->高中讲的“集合”
- |----HashSet:作为Set接口的主要实现类;线程不安全的;可以存储null值
- |----LinkedHashSet:作为HashSet的子类;遍历其内部数据时,可以按照添加的顺序遍历
在添加数据的同时,每个数据还维护了两个引用,记录此数据前一个数据和后一个数据。 对于频繁的遍历操作,LinkedHashSet效率高于HashSet. - |----TreeSet:可以照添加对象的指定属性,进行排序。向TreeSet中添加的数据,要求是相同类的对象。
3. List接口
增:add(Object obj)
删:remove(int index) / remove(Object obj)
改:set(int index, Object ele)
查:get(int index)
插:add(int index, Object ele)
长度:size()
遍历:① Iterator迭代器方式
② 增强for循环**
③ 普通的循环**
2.1 ArrayList的源码分析:
jdk7中,创建对象时,底层创建了长度是10的Object[]数组elementData
当调用add方法不够时,默认情况下,扩容为原来的容量的1.5倍,同时需要将原有数组中的数据复制到新的数组中。
jdk8中是调用add方法时才创建了长度是10的Object[]数组elementData,属于不安全的懒汉式
2.2 LinkedList的源码分析:
内部声明了Node类型的first和last属性,默认值为null
2.3 Vector的源码分析:
jdk7和jdk8中通过Vector()构造器创建对象时,底层都创建了长度为10的数组。
在扩容方面,默认扩容为原来的数组长度的2倍。
关于ArrayList和Arrays.ArrayList():
https://blog.csdn.net/Tracycater/article/details/77592472?locationNum=2&fps=1
调用Arrays.asList()产生的List中add、remove方法时报异常,这是由于Arrays.asList()返回的是Arrays的内部类ArrayList, 而不是java.util.ArrayList。Arrays的内部类ArrayList和java.util.ArrayList都是继承AbstractList,remove、add等方法在AbstractList中是默认throw UnsupportedOperationException而且不作任何操作。java.util.ArrayList重写这些方法而Arrays的内部类ArrayList没有重写
4. Set接口
4.1 元素添加过程:(以HashSet为例)
我们向HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值,
此哈希值接着通过某种算法计算出在HashSet底层数组中的存放位置(即为:索引位置,判断
数组此位置上是否已经元素:
如果此位置上没其他元素,则元素a添加成功。 --->情况1
如果此位置上其他元素b(或以链表形式存在的多个元素,则比较元素a与元素b的hash值:
如果hash值不相同,则元素a添加成功。--->情况2
如果hash值相同,进而需要调用元素a所在类的equals()方法:
equals()返回true,元素a添加失败
equals()返回false,则元素a添加成功。--->情况2
对于添加成功的情况2和情况3而言:元素a 与已经存在指定索引位置上数据以链表的方式存储。
jdk 7 :元素a放到数组中,指向原来的元素。
jdk 8 :原来的元素在数组中,指向元素a
总结:七上八下
4.2 存储对象的要求
要求:向Set(主要指:HashSet、LinkedHashSet)中添加的数据,其所在的类一定要重写hashCode()和equals()
要求:重写的hashCode()和equals()尽可能保持一致性:相等的对象必须具有相等的散列码
- 重写两个方法的小技巧:对象中用作 equals() 方法比较的 Field,都应该用来计算 hashCode 值。
TreeSet:
1.自然排序中,比较两个对象是否相同的标准为:compareTo()返回0.不再是equals().
2.定制排序中,比较两个对象是否相同的标准为:compare()返回0.不再是equals().
4.3 HashSet和HashMap的关系和区别
- | HashMap | HashSet |
| ----------------- | --------------- |
| 实现了Map接口 | 实现Set接口 | - 在jdk8中,HashSet使用的是HashMap来存的
//HashSet源码
...
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
...
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
...
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}因此它们底层存储的大小默认是一致的
default initial capacity (16) and load factor (0.75)
- HashMap中,key如果是null会变成0:
// HashMap
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}- 在不断的添加过程中,会涉及到扩容问题,当超出临界值(且要存放的位置非空)时,扩容。默认的扩容方式:扩容为原来容量的2倍,并将原的数据复制过来。
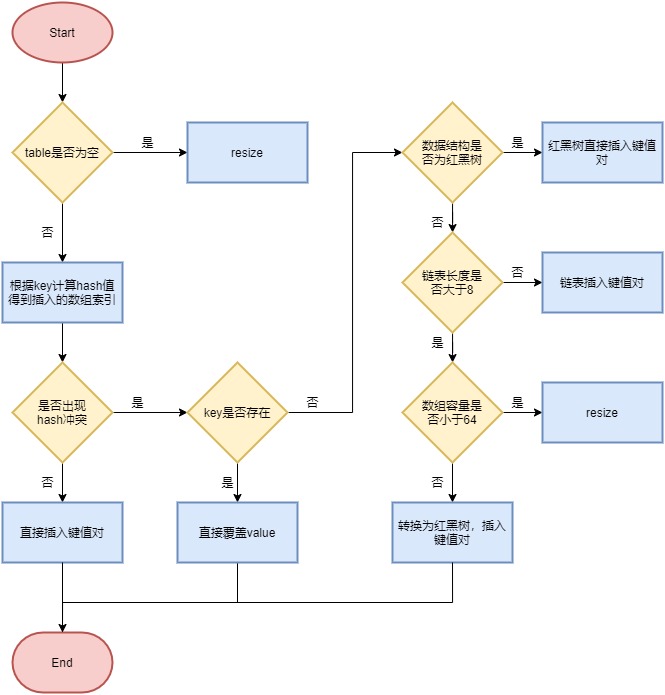
4.3 补充 HashMap扩容判断图
双列集合框架:Map
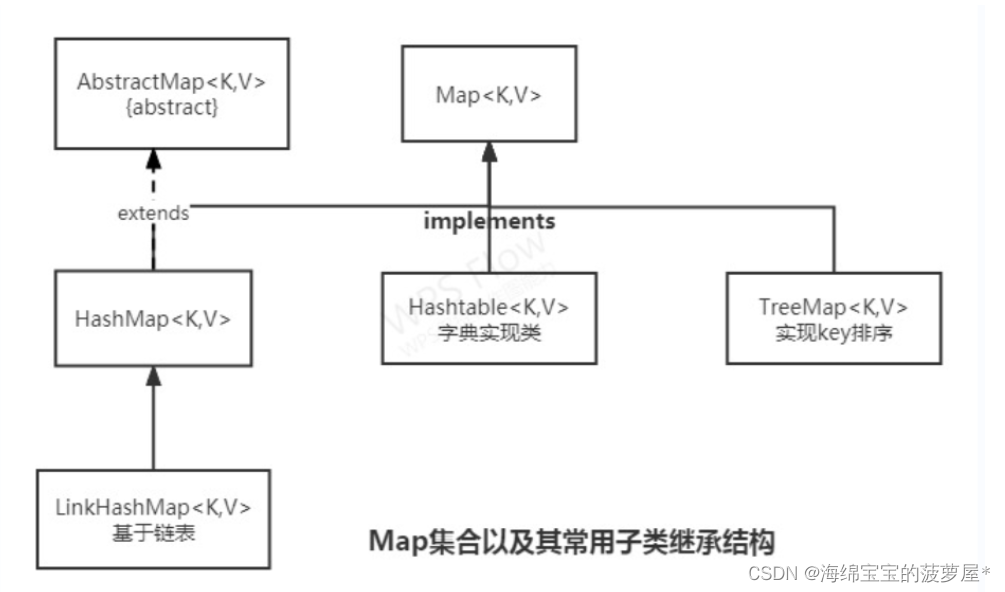
1.常用实现类结构
|----Map:双列数据,存储key-value对的数据 ---类似于高中的函数:y = f(x)
|----HashMap:作为Map的主要实现类;线程不安全的,效率高;存储null的key和value
- |----LinkedHashMap:保证在遍历map元素时,可以照添加的顺序实现遍历。
原因:在原的HashMap底层结构基础上,添加了一对指针,指向前一个和后一个元素。
对于频繁的遍历操作,此类执行效率高于HashMap。
- |----LinkedHashMap:保证在遍历map元素时,可以照添加的顺序实现遍历。
- |----TreeMap:保证照添加的key-value对进行排序,实现排序遍历。此时考虑key的自然排序或定制排序
底层使用红黑树 |----Hashtable:作为古老的实现类;线程安全的,效率低;不能存储null的key和value
- |----Properties:常用来处理配置文件。key和value都是String类型
2.存储结构
Map中的key:无序的、不可重复的,使用Set存储所的key ---> key所在的类要重写equals()和hashCode() (以HashMap为例)
Map中的value:无序的、可重复的,使用Collection存储所的value --->value所在的类要重写equals()
一个键值对:key-value构成了一个Entry对象。
Map中的entry:无序的、不可重复的,使用Set存储所的entry
3.常用方法
- 添加:put(Object key,Object value)
- 删除:remove(Object key)
- 修改:put(Object key,Object value)
- 查询:get(Object key)
- 长度:size()
- 遍历:keySet() / values() / entrySet() )/Map.Entry<Character, Integer>
- 是否包含:contains()
4.HashMap底层属性说明
DEFAULT_INITIAL_CAPACITY : HashMap的默认容量,16
DEFAULT_LOAD_FACTOR:HashMap的默认加载因子:0.75
threshold:扩容的临界值,=容量填充因子:16 0.75 => 12(大于临界值才会扩容)
TREEIFY_THRESHOLD:Bucket中链表长度大于该默认值,转化为红黑树:8
MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量:64
多线程
继承Thread类的方式
重写继承hread类的run()方法,
新建该子类的对象,
然后直接该子类对象.start()来调用
实现Runnable接口的方式
创建一个实现该接口的类,并用该类重写其中的run()方法
新建类的对象
将该对象作为参数传给Thread类构造器
使用Thread.start()调用
实现Runnable. Callable接口的方式(jdk5以后)
和上面一样先实现Callable接口,重写其中的call()方法
新建类的对象
需要新建FutureTask构造器,并且将上面对象作为参数传入
新建Thread构造器对象,并将FutureTask作为参数传入,
使用Thread.start()调用。
public static void main(String[] args) throws Exception {
try {
//使用匿名内部类创建Callable
Callable callable = () -> "hello call";
FutureTask futureTask = new FutureTask(callable);
//执行线程
new Thread(futureTask).start();
if (!futureTask.isDone()) {
//获取返回值
System.out.println(futureTask.get());
}
} catch (Exception e) {
e.printStackTrace();
}
}对比起Runnable, Callable可以通过FutureTask.get()获取Callable中重写的call()方法的返回值
并且可以将异常抛出。通过FutureTask构造器还可以实现很多效果。
线程池
public class ThreadPool {
public static void main(String[] args) {
//1. 提供指定线程数量的线程池
ExecutorService service = Executors.newFixedThreadPool(10);
ThreadPoolExecutor service1 = (ThreadPoolExecutor) service;
//设置线程池的属性
// System.out.println(service.getClass());
// service1.setCorePoolSize(15);
// service1.setKeepAliveTime();
//2.执行指定的线程的操作。需要提供实现Runnable接口或Callable接口实现类的对象
service.execute(new NumberThread());//适合适用于Runnable
service.execute(new NumberThread1());//适合适用于Runnable
// service.submit(Callable callable);//适合使用于Callable
//3.关闭连接池
service.shutdown();
}
}
说明:
* 好处:
* 1.提高响应速度(减少了创建新线程的时间)
* 2.降低资源消耗(重复利用线程池中线程,不需要每次都创建)
* 3.便于线程管理
* corePoolSize:核心池的大小
* maximumPoolSize:最大线程数
* keepAliveTime:线程没任务时最多保持多长时间后会终止
### 线程池中submit() 和 execute()方法有什么区别?
execute()没有返回值;而submit()有返回值submit()的返回值Future调用get()方法时,可以捕获处理异常。而execute()没有返回值不能捕获异常。多线程如何共享变量?
1.synchronized
使用synchronized时,会先将主内存刷新到工作内存中,执行完毕后再刷新回主内存中
因此使用synchronized可以保证执行的时候获得主内存中的最新数据
2.volatile
可以事实获取主内存中的最新数据,但是不能保证原子性
死锁
多个进程被阻塞,互相持有互相所需的资源不放,且等待的进程也处于阻塞,不能被终止
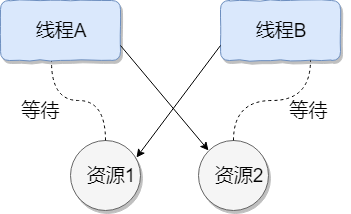
死锁的四个条件
- 互斥:一个资源(比如某个代码块)任意一个时刻只由一个线程占用。
- 请求与保持:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺(不可抢占):线程已获得的资源在末使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
- 循环等待:若干进程之间形成一种头尾相接的循环等待资源关系。
避免死锁
破坏任意一个条件就不会造成死锁
- 破坏互斥条件 这个条件我们没有办法破坏,因为我们用锁本来就是想让他们互斥的(临界资源需要互斥访问)
- 破坏请求与保持条件 一次性申请所有的资源。
- 破坏不剥夺条件 占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
- 破坏循环等待条件 靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
- 锁排序法:(必须回答出来的点)通过指定锁的获取顺序,比如规定,只有获得A锁的线程才有资格获取B锁,按顺序获取锁就可以避免死锁。这通常被认为是解决死锁很好的一种方法。
- 使用显式锁中的ReentrantLock.try(long,TimeUnit)来申请锁
什么是锁
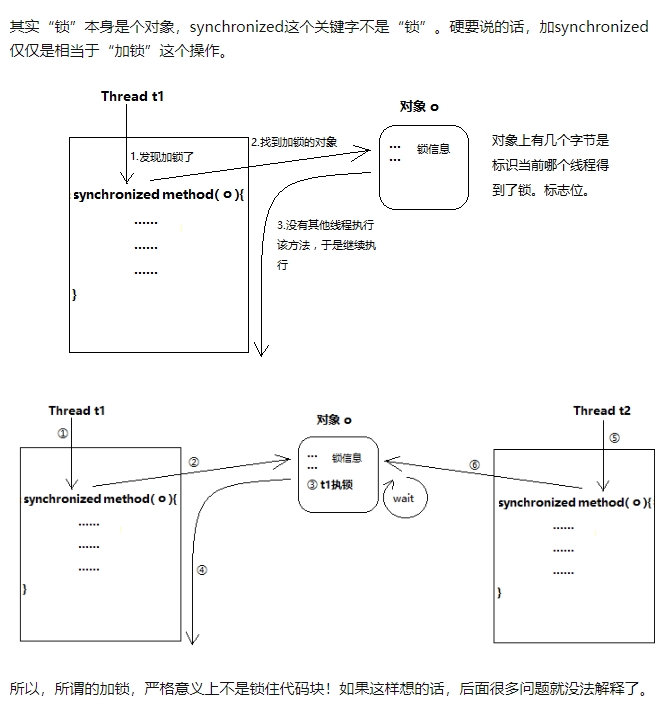
使用 synchronized避免死锁
synchronized可以修饰方法、对象、类,当一个线程进入该代码块时,其他线程如果到达此处会被阻塞,直到代码块中的线程出来。
关于volatile
volatile特点是可见性
不同于synchronized,它解决的是内存可见性问题,会使得所有对 volatile 变量的读写都直接写入主存,即 保证了变量的可见性。
volatile只能修饰变量,而synchronized可以修饰变量、方法、类。
线程的生命周期:
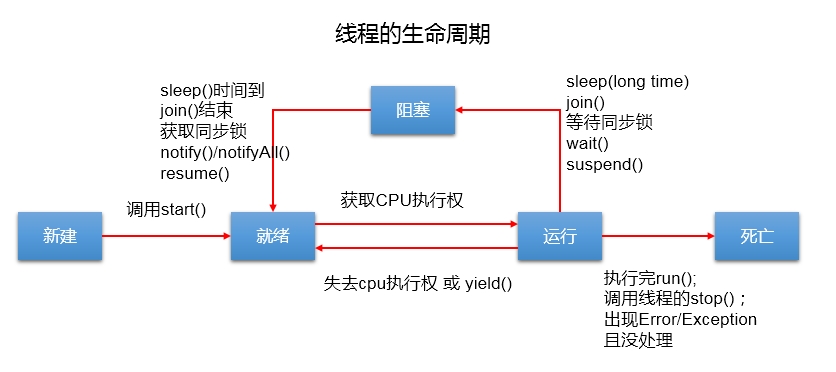
- 新建:当线程对象对创建后,即进入了新建状态,如:Thread t = new MyThread();
- 就绪:当调用线程对象的start()方法(t.start();),线程即进入就绪状态。处于就绪状态的线程,只是说明此线程已经做好了准备,随时等待CPU调度执行,并不是说执行了t.start()此线程立即就会执行;
- 运行:当CPU开始调度处于就绪状态的线程时,此时线程才得以真正执行,即进入到运行状态。注:就 绪状态是进入到运行状态的唯一入口,也就是说,线程要想进入运行状态执行,首先必须处于就绪状态中;
阻塞:处于某种原因暂时停止执行,等待cpu的再次调度
- 等待阻塞:运行状态中的线程执行wait()方法,使本线程进入到等待阻塞状态;
- 同步阻塞 — 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态;
- 其他阻塞 — 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时. join()等待线程终止或者超时. 或者I/O处理完毕时,线程重新转入就绪状态。
- 死亡:线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
泛型
泛型方法的格式:
[访问权限] <泛型> 返回类型 方法名([泛型标识 参数名称]) 抛出的异常
- Java 中不支持泛型数组,需要通过Object强转
public class Order<T> {
String orderName;
int orderId;
//类的内部结构就可以使用类的泛型
T orderT;
public Order(){
//编译不通过
// T[] arr = new T[10];
//编译通过
T[] arr = (T[]) new Object[10];
}
}- 泛型只能是类,不能用基本数据类型填充。但可以使用包装类填充
- 在静态方法中不能使用类的泛型,但是泛型方法可以是静态的
// static的方法中不能声明泛型
//public static void show(T t) {
//
//}
// 可以当作静态方法使用
public static <T> void getW(T t) {
System.out.println(t);
}java8中
ArrartList<Customer> cu = new ArrartList<>(); //可以省略右边的泛型 ArrartList<Customer> cu = new ArrartList<Customer>(){ //但是匿名函数的时候不可省略(java10可以省) ... };
通配符
- 通配符 ? 是所有类的父类
- 通配符<?>不能用在泛型方法,泛型类的声明上
<? extends Number>
只允许泛型为Number及Number子类的引用调用
<? super Number>
只允许泛型为Number及Number父类的引用调用
<? extends Comparable>
只允许泛型为实现Comparable接口的实现类的引用调用
// 编译错误:不能用在创建对象上,右边属于创建集合对象
//ArrayList<?> list = new ArrayList<?>();
// null是任何类型的成员
ArrayList<?> list = null;
Collection<?> c = new ArrayList<String>();
c.add(new Object()); // 编译时错误
// 因为我们不知道c的元素类型,我们不能向其中添加对象。
// add方法有 泛型参数 作为集合的元素类型。
// 除了null,没有任何对象可以: ? t = new Object(),反射
获取class的方法:
- 类.class()
- 实例对象.getCalss()
- Class.forName("类所在位置")
- 类的加载器ClassLoader
ClassLoader classLoader = 当前类.class.getClassLoader()
classLoade.loadClass("目标类所在位置")
通过Proxy.newProxyInstance()创建代理类及对象
public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h){}ClassLoader loader 为被代理类的 类的加载器
Class<?>[] interfaces 为被代理类的 实现的接口
InvocationHandler h 实现了InvocationHandler接口并且重写了invoke()方法的类
ps:如果该类没有实现的接口就只能使用CGLIB了
一些别的note
- char型使用 ‘0’或‘\u0000’表示
- long型表示带L(l)
- float表示带f
- char,short,byte做运算时都是使用int
进制表示:
int a = 0b10111; 0b开头表示二进制数
int b = 0127; 0开通表示8进制数
int c = 0x187Fde; 0x或者0X开头表示16机制数- "%"取余的符号与被模数相同
- +=、%=、-=不会改变数据类型
- &逻辑与:两边都会执行,且都为true时才为真
- &&短路与:左边如果是false了就不看右边了
- 方法中不能定义方法
- 子类的权限可以大于父类
- 子类不能重写父类的private方法
- 父类返回值是基本数据类型的时候,子类重新的方法必须返回相同类型(java3.OverClassTest)
(如果返回是个类,则可以是它的子类,不能是父类(不是多态!))~为何不能是范围更小的父类~ - 多态只适用于方法,不适于属性
- 内部类调用外部类的方法:外部类.this.外部方法
- 内部类静态类和非静态类调用方法
class Person{
static class Dog{
}
class Bird{
}
}
// 静态类
Peson.Dog dog = new Person.Dog();
// 非静态
Person p = new Person();
p.Bird bird = p.new Person.Bird();//或者 p.new Bird()- ObjectOutputStream和ObjectInputStream不能序列化static和transient修饰的成员变量
Properties获取流的两种方式:
Properties pros = new Properties(); //方式1: //InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("dbcp.properties"); //方式2: FileInputStream is = new FileInputStream(new File("src/dbcp.properties")); pros.load(is);- 要想快速的打印一个二维数组的数据元素的列表,可以调用:
System.out.println(Arrays.deepToString(a)) 为什么重写 equals 方法必须重写 hashcode 方法 ?
在hashmap中,判断的时候先根据hashcode进行的判断,相同的情况下再根据equals()方法进行判断。如果只重写了equals方法,而不重写hashcode的方法,会造成hashcode的值不同,而equals()方法判断出来的结果为true。
在Java中的一些容器中,不允许有两个完全相同的对象,插入的时候,如果判断相同则会进行覆盖。这时候如果只重写了equals()的方法,而不重写hashcode的方法,Object中hashcode是根据对象的存储地址转换而形成的一个哈希值。这时候就有可能因为没有重写hashcode方法,造成相同的对象散列到不同的位置而造成对象的不能覆盖的问题。
- 泛型只存在于编译阶段,而不存在于运行阶段
- 红黑树时间复杂度为
o(logn) int[][] a= new int[5][5];矩阵内默认数值都是0- 声明为 final 、 static 、 private 的方法不能被重写
Integer的一些底层以及部分“==”可以成立的问题:
Integer本身是一个类,为了增加检索速度,创建时就会在内存中建立128—-127的对象,要用的时候直接索引,但是超过这个数值范围的时候就会重新建立对应的类,因此在这个范围里使用"=="可以成立
java的内部类
- 局部内部类:局部内部类是定义在外部类的局部位置,比如方法中,并且有类名。
外部类访问局部内部类的方式:创建对象再访问
public class TestDemo {
public static void main(String[] args) {
Person person = new Person();
person.method2();
//不能直接访问局部内部类
//person.student;//报错:Cannot resolve symbol 'student'
}
}
class Person{//外部类
private String name = "张三";
private int age = 20;
private void method1(){
System.out.println("外部类中的method1方法");
}
public void method2(){
final class Student{//局部内部类可以加fianl关键字
private String name = "王五";
public void method3(){
System.out.println(name);//遵循就近原则
System.out.println(Person.this.name);//同名时访问外部成员
method1();//可以访问外部类中的成员
}
}
/**
* 外部类访问局部内部类的方式:创建对象再访问
*/
Student student = new Student();
student.method3();
}
}匿名内部类:匿名内部类是没有名称的内部类。
public class TestDemo02 { public static void main(String[] args) { People people = new People(); people.method(); } } class People{ private String name; public void method(){ Behavior student = new Behavior() { @Override public void eat() { System.out.println("学生韩梅梅正在吃饭"); } }; student.eat(); Behavior teacher = new Behavior() { @Override public void eat() { System.out.println("老师李华正在吃饭"); } }; teacher.eat(); } } interface Behavior{ public void eat(); }上面的匿名内部类的操作步骤和局部内部类是一样的,只不过简化了代码而已。
- 实例内部类:对于内部类来说,和普通的成员变量是同一等级的,也依赖于对象。所以,需要外部类对象的引用才能进行内部类的实例化。实例内部类不能使用抽象和静态修饰!
静态内部类:静态内部类就是用saitic关键字修饰的内部类类,是与类共享的,所以静态内部类的对象不依赖于外部类的对象。
不同于实例内部类,可直接通过类创建。package people; //外部类 public class Person { int age; static String name="小明"; public void eat(){ System.out.println("我是Person中的非静态方法"); } public static void run(){ System.out.println("我是Person中的静态方法"); } public Heart getHeart(){ new Heart().em=20; return new Heart(); } //静态内部类 static class Heart{ static int age=13; int em=10; public static void say(){ System.out.println("Hello"+name); } public String beat(){ //通过对象实例来调用非静态成员 new Person().eat(); //可以直接调用外部类的静态成员 run(); //若调用外部类的同名熟悉,需要通过对象实例来调用 //格式:new 外部类名().属性名;如new Person().age return age+"心脏再跳动!"; } } } /** *调用 */ package people; //将内部类实例化 public class PeopleTest { public static void main(String[] args) { Person lili=new Person(); lili.age=12; //直接获取静态内部类对象实例 Person.Heart myHeat=new Person.Heart(); System.out.println(myHeat.beat()); Person.Heart.say(); } }
内部类补充:
- java允许我们在一个类里面定义静态类。比如内部类(nested class)。把nested class封闭起来的类叫外部类。在java中,我们不能用static修饰顶级类(top level class)。只有内部类可以为static。
- java中普通的顶级类是不能使用static关键字修饰的。只有内部类可以使用static修饰,也可以不使用staitc关键字修饰。
静态内部类可以直接创建实例,而普通的内部类需要先创建外部类的实例,接着利用该实例才可以接着创建该内部类
class Main { // 怎么创建静态内部类和非静态内部类的实例 public static void main(String args[]) { // 创建静态内部类的实例 OuterClass.NestedStaticClass printer = new OuterClass.NestedStaticClass(); // 为了创建非静态内部类,我们需要外部类的实例 OuterClass outer = new OuterClass(); OuterClass.InnerClass inner = outer.new InnerClass(); // 我们也可以结合以上步骤,一步创建的内部类实例 OuterClass.InnerClass innerObject = new OuterClass().new InnerClass(); } } class OuterClass{ // 静态内部类 public static class NestedStaticClass{ } // 非静态内部类 public class InnerClass{ } }
IO、NIO有什么区别?
https://blog.csdn.net/yhj_911/article/details/108274512
IO是面向流的,NIO是面向缓冲区的。
IO包括:File、OutputStream、InputStream、Writer,Reader。**
NIO三大核心:selector(选择器),channel(通道),buffer(缓冲区)
**NIO与IO区别在于,IO面向流,NIO面向缓冲区。IO是阻塞,NIO是非阻塞。
sleep()方法和wait()
sleep()方法和wait()方法都用来改变线程的状态,能够让线程从运行状态,转变为休眠状态。sleep()方法可以在任何地方调用,而wait()方法只能在同步代码块或同步方法中使用(即使用synchronized关键字修饰的)。- 这两个方法都在同步代码块或同步方法中使用时,
sleep()方法不会释放对象锁。而wait()方法则会释放对象锁。
java的内存模型和synchronized
java的内存模型规定了所有的变量都存储在主内存中,每个线程拥有自己的工作内存,工作内存保存了该线程使用到的变量的主内存拷贝,线程对变量所有操作,读取,赋值,都必须在工作内存中进行,不能直接写主内存变量,线程间变量值的传递均需要主内存来完成。
使用synchronized时,会先将主内存刷新到工作内存中,执行完毕后再刷新回主内存中
字节流与字符流
字节流:
- 以 stream 结尾都是字节流;
- InputStream 是所有字节输入流的父类,OutputStream 是所有字节输出流的父类;
- 读写的时候按字节读写,主要用来处理字节或二进制对象;
- 字节流在操作时不会用到缓冲区(内存);
- 在硬盘上的所有文件都是以字节形式存在的;
字符流:在字节流的基础上,加上编码,因为字节流在操作字符时,有可能会有中文导致的乱码
- 以 reader 和 writer 结尾;
- Reader 是字符输入流的父类,Writer 是字符输出流的父类;
- 读写的时候按字符读写,主要用来处理字符或字符串;
- 字符流在操作时需要用到缓冲区
java中正则匹配的全文匹配和部分匹配
- 全文匹配,即全部字符匹配才能返回true
String abc = "regex.1234561";
boolean matches = abc.matches("^[a-z]{5}.[0-9]+$");
// 输出该结果为true
System.out.println(matches);- 部分匹配,存在部分匹配值可以返回true,常用的
String.replaceAll(regex, replaceStr);中其实也是用的是部分匹配进行的替换
String abc = "regex.1234561";
Pattern pattern = Pattern.compile("[a-z]{4}.[0-9]+");
Matcher matcher = pattern.matcher(abc);
while (matcher.find()) {
// 得到符合的匹配egex.1234561
System.out.println(matcher.group());
}Character常用方法
Character.isletter(char)判断该字符是否为子母
键值对排序的方法:利用TreeMap
import java.util.*;
public class TreeMapExample {
public static void main(String[] args) {
// 创建 TreeMap 对象
TreeMap<String, Integer> treeMap = new TreeMap<>();
// 添加元素
treeMap.put("apple", 2);
treeMap.put("banana", 3);
treeMap.put("orange", 1);
// 遍历 TreeMap,按键排序
for (Map.Entry<String, Integer> entry : treeMap.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
}给ArrayList自定义排序
ArrayList<Character> letter = new ArrayList<>();
//单词从小到大排序
letter.sort(new Comparator<Character>() {
public int compare(Character o1, Character o2) {
return Character.toLowerCase(o1) - Character.toLowerCase(o2);
}
});对ArrayList进行排序
import java.util.*;
public class ArrayListSortExample {
public static void main(String[] args) {
// 创建 ArrayList 对象
ArrayList<Integer> arrayList = new ArrayList<>();
// 添加元素
arrayList.add(3);
arrayList.add(1);
arrayList.add(2);
// 对元素进行排序
Collections.sort(arrayList);
// 遍历 ArrayList,按升序排序
for (int element : arrayList) {
System.out.println(element);
}
}
}对char数组进行排序
import java.util.Arrays;
public class CharArraySortExample {
public static void main(String[] args) {
// 定义一个 char 数组
char[] charArray = {'c', 'a', 't', 'd', 'o', 'g'};
// 对 char 数组按字母顺序排序
Arrays.sort(charArray);
// 输出排序后的 char 数组
for (char c : charArray) {
System.out.print(c + " ");
}
}
}
/// a c d g o t一些不常用的进制转换:
Long.parseLong(String s,int radix):将一个指定进制的字符串转换成十进制的字符串转换成的Long数字,radix为指定进制Integer.toBinaryString(num):将十进制的int数字转换成二进制的字符串
target
1.MySQL锁机制
表锁。开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
行锁。开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
在MySQL中只有InnoDB存储引擎可以使用行锁。
lock table有如下两种表达方式:
- lock table xxx read,只读方式锁住xxx,该表只能被select,不能被修改。如果在lock时,该表上存在事务,则lock语句挂起,直到事务结束。多个会话可以同时对表执行该操作。
- lock table xxx write,读写方式锁住xxx,lock table的会话可以对表xxx做修改及查询等操作,而其他会话不能对该表做任何操作,包括select也要被阻塞。
可以同时锁住多个表。