DML(data manipulation language)是数据操纵语言:它们是SELECT、UPDATE、INSERT、DELETE,就象它的名字一样,这4条命令是用来对数据库里的数据进行操作的语言。
DDL(data definition language)是数据定义语言:DDL比DML要多,主要的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表(TABLE)的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用。
DCL(DataControlLanguage)是数据库控制语言:是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)语句。
DML
DML操作中,DELETE FROM 可以通过SET autocommit = FALSE;来使用ROLLBACK,在commit之前能够回滚数据
SELECT
sql92语法:
SELECT (distinct)....,....,....(存在聚合函数)
FROM ...,....,....
WHERE 多表的连接条件 AND 不包含聚合函数的过滤条件
GROUP BY ...,....
HAVING 包含聚合函数的过滤条件
ORDER BY ....,...(ASC / DESC )
LIMIT ...,....sql99语法:
除了GROUP BY和LIMIT外,其他位置都可以申明子查询
SELECT (distinct) ....,....,....(存在聚合函数)
FROM ... (LEFT / RIGHT)JOIN ....ON 多表的连接条件
(LEFT / RIGHT)JOIN ... ON ....
WHERE 不包含聚合函数的过滤条件
GROUP BY ...,....
HAVING 包含聚合函数的过滤条件
ORDER BY ....,...(ASC / DESC )
LIMIT ...,....SQL语句的执行过程:
FROM ...,...-> (LEFT/RIGNT JOIN) ->ON -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT -> ORDER BY -> LIMIT
数据增删改
# 添加数据
INSERT INTO emp1[(字段名)]
[
VALUES
(4,'Jim',5000),
(5,'张俊杰',5500);
];
[
# 直接插入查询结果
SELECT employee_id,last_name,salary,hire_date # 查询的字段一定要与添加到的表的字段一一对应
FROM employees
WHERE department_id IN (70,60);
]
# 更新数据
UPDATE emp1
SET hire_date = CURDATE(),salary = 6000
WHERE id = 4;
# 删除
DELETE [emp1] FROM emp1
WHERE id = 1; # 不指定某行就情况整个表
# MySQL8的新特性:计算列
CREATE TABLE test1(
a INT,
b INT,
c INT GENERATED ALWAYS AS (a + b) VIRTUAL #字段c即为计算列
);
约束
# 使用添加约束的方法
ADD CONSTRAINT constraint_name
[UNIQUE(字段列表)]
[UNIQUE KEY(字段列表);]
/
ADD UNIQUE KEY(字段列表);- 重点:非空约束 唯一性约束,主键约束,默认值约束
# 建表时
CREATE TABLE 表名称(
字段名 数据类型,
字段名 数据类型 NOT NULL,
字段名 数据类型 [unique][unique key],
字段名 数据类型 primary key(字段名) [auto_increment],
字段名 数据类型 default 默认值,
[[constraint 约束名] unique key(字段名)],
/
[unique key(字段列表)],
primary key(字段列表) [auto_increment]# 复合主键
);
# 建表后
alter table 表名称 modify 字段名 数据类型 not null;
alter table 表名称 modify 字段名 字段类型 unique;
/
alter table 表名称 add unique key(字段列表);
ALTER TABLE 表名称 MODIFY [COLUMN] 字段名 字段类型 PRIMARY KEY;
/
ALTER TABLE 表名称 ADD PRIMARY KEY(字段列表);
alter table 表名称 modify 字段名 数据类型 default 默认值;
# 复合
ALTER TABLE 表名称 MODIFY [COLUMN]
constraint 约束名 ...规范:
- VALUES 中字符串用''
- SELECT 中用字符串""
- Mysql在win中 字符串也忽视大小写
- 取模%时,答案的正负只和被模数相关
- 字符串隐式转化不成功的话,会被转成数值0
LIKE 中 %代表0或多,_代表未知占位
- ESCAPE指定转义符
- and优先级高于or
- 别名只能在ORDER BY中使用
- Mysql不支持sql92中外连接的+,也不支持sql99的FULL OUTER JOIN
- SELECT出现的非组函数的字段必须声明在GROUP BY中,反之可以不出现。(不一定)
- 聚合函数不能嵌套
- 多行子查询的 IN()中,如果子表中有NULL值,则任何值与其判断都会被判定为真
在DRAP TABLE中 5.7和8.0的不同:
5.7 中如果 DRAP TABLE book1,book2 若是book2不存在导致执行失败,book1也会被删除
8.0 中 DRAP TABLE book1,book2 即便是book2不存在导致执行失败,book1也不会删除
- DESC table 中,int(4) 其中的4是包括了符号的,而float(5,2),中的5是不包括符号的
由于二进制不能准确表示小数,所以float和double都是不精准的,
而DECIMAL是用字符串形式存储的
DATETIME 和 TIMESTAMP的区别
- TIMESTAMP占用内存更小,可存储的范围更小
- TIMESTAMP中包含时区信息
- char 不存空格,而VARCHAR类型的字段数据时,会保留数据尾部的空格。
- char(5),VARCHAR(5) 中的5皆代表字符数(SQL8.0)
类型
| 类型 | 特点 | 空间上 | 时间上 | 适用场景 |
|---|---|---|---|---|
| CHAR(M) | 固定长度 | 浪费存储空间 | 效率高 | 存储不大,速度要求高 |
| VARCHAR(M) | 可变长度 | 节省存储空间 | 效率低 | 非CHAR的情况 |
- BLOB和TEXT类型容易造成空间空洞
- sql中的“?”称为占位符,JAVA中的泛型中的"?"称为通配符
- sql中有个日期的隐式转换,它会把字符串"1999-1-1"自动转成Date类
DDL
# 创建库、表
CREATE DATABASE [IF NOT EXISTS] 数据库名 [CHARACTER SET 'UTF8']
CREATE TABLE dept01
[
(id INT(7),
`name` VARCHAR(25));
]
[
AS
SELECT *
FROM atguigudb.`departments`;
]
# 修改
ALTER TABLE emp01
[# 修改列
MODIFY last_name VARCHAR(50);
DESC emp01;
]
[# 增加列
ADD test_column VARCHAR(20);
]
[# 删除列
DROP COLUMN department_id
]
[# 重命名并重定义内部属性列
CHANGE department_name dept_name varchar(15);
]
#删除表、库
DROP TABLE [IF EXISTS] emp01;
DROP DATABASE [IF EXISTS] 数据库名;
# 表重命名
RENAME TABLE emp02 TO emp01;
/
ALTER TABLE emp02 RENAME TO emp01
# 清空表
# DELETE FROM 可以通过SET autocommit = FALSE;来使用ROLLBACK,在commit之前能够回滚数据
TRUNCATE TABLE emp2;
/
DELETE FROM emp2;
阿里开发规范: 【参考】TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少,但 TRUNCATE 无 事务且不触发 TRIGGER,有可能造成事故,故不建议在开发代码中使用此语句。 说明:TRUNCATE TABLE 在功能上与不带 WHERE 子句的 DELETE 语句相同。
补充
ALTER TABLE MODIFY和ALTER TABLE CHANGE的区别
1、改列的类型而不是名称, CHANGE语法仍然要求旧的和新的列名称,即使旧的和新的列名称是一样的。
例如: ALTER TABLE t1 CHANGE b b BIGINT NOT NULL.
2、使用MODIFY来改变列的类型,此时不需要重命名:
例如: ALTER TABLE t1 MODIFY b BIGINT NOT NULL。
高级
Linux
- desc 表名 显示某表信息,用于sql操作界面
- 查看sql版本 sqladmin --version
- sql的root若是想能够远程访问需要把mysql数据库中的user表中root对应的host列改成%,然后使用sql语句flush privileges刷新
InnoDB优点
- 支持外键
- 可以处理事务
- 如果更新、删除操作多,应使用InnoDB,它是为处理大数据量设计的
- 可以进行行锁
- 数据和索引合一
- 自适应 Hash索引
MyISam
- 索引和数据分离
InnoDb的不足
- 写的处理效率差一些
- 对内存要求高
MyISAM的优点
- 对SELECT、INSERT为主的应用处理速度更快
- 有额外的常数存储,故count(*)的查询效率高
MyISAM的不足
- 不支持事务
- 只支持表级锁
- 崩溃后无法安全恢复
分清聚簇索引、二级索引(非聚簇索引、辅助索引)、联合索引(非聚簇索引)
- 聚簇索引:B+树的 叶子节点 存储的是完整的用户记录。
- 二级索引:在建立聚簇索引B+树的基础上,再以每个列和主键构建一个二级索引B+树
- 联合索引:是同时为多个列建立索引,比如C2,C3
InnoDB的B+树索引的注意事项
根页面位置万年不动
数据从根节点向下复制衍生,根节点的物理位置不会变
内节点中目录项记录的唯一性
对二级索引或者联合索引来说,当对比的字段都一致时,要在目录页面(非叶子节点)中加入主键来做对比
- 一个页面最少存储2条记录

索引
CREATE TABLE table_name [col_name data_type]
[UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY] [index_name] (col_name [length]) [ASC |
DESC]- UNIQUE 、 FULLTEXT 和 SPATIAL 为可选参数,分别表示唯一索引、全文索引和空间索引;
- INDEX 与 KEY 为同义词,两者的作用相同,用来指定创建索引;
- index_name 指定索引的名称,为可选参数,如果不指定,那么MySQL默认col_name为索引名;
- col_name 为需要创建索引的字段列,该列必须从数据表中定义的多个列中选择;
- length 为可选参数,表示索引的长度,只有字符串类型的字段才能指定索引长度;
- ASC 或 DESC 指定升序或者降序的索引值存储。
聚簇索引和非聚簇索引
聚簇索引:B+树结构,且只有主键
- 主键索引
非聚簇索引:可能是B+树结构,有主键和其他列(就算以一个列做索引也会自动带上主键的)
- 普通索引
- 二级索引:在建立聚簇索引B+树的基础上,再以每个列和主键构建一个二级索引B+树
- 联合索引:是同时为多个列建立索引,比如C2,C3
- 前缀索引:把很长字段的前面的公共部分作为一个索引,order by不支持前缀索引
回表:指类似二级索引某列后,再通过主键去主键索引出其他列信息
ps 全文索引只能用在char类
pss MyISAM无论主键索引还是二级索引都是非聚簇索引,而InnoDB的主键索引是聚簇索引,二级索引是非聚簇索引。我们自己建的索引基本都是非聚簇索引
查看MySQL语句有没有用到索引
EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND title='Senior Engineer' AND from_date='1986-06-26';
最左前缀原则
where查询中,被查询得越频繁的越应该放在最左边,mysql会向右一直匹配到(>、<、between、like)就停止匹配,因此只要检测到这些符号就不能用索引了
MySQL 执行查询的过程
- 客户端通过 TCP 连接发送连接请求到 MySQL 连接器,连接器会对该请求进行权限验证及连接资源分配
- 查缓存。(当判断缓存是否命中时,MySQL 不会进行解析查询语句,而是直接使用 SQL 语句和客户端发送过来的其他原始信息。所以,任何字符上的不同,例如空格、注解等都会导致缓存的不命中。)
- 语法分析(SQL 语法是否写错了)。 如何把语句给到预处理器,检查数据表和数据列是否存在,解析别名看是否存在歧义。
- 优化。是否使用索引,生成执行计划。
- 交给执行器,将数据保存到结果集中,同时会逐步将数据缓存到查询缓存中,最终将结果集返回给客户端。
三范式
第一范式:行不重复,列不可再分
字段不可分,每个字段是原子级别的,第一个字段为ID,它就是ID不能在分成两个字段了,不能说我要把这个人的ID、名称、班级号都塞在一个字段里面,这个是不合适的,对以后的应用造成很大影响
第二范式:非主依主
表必须符合第一范式,非主键列必须依赖主键列。
每个表只描述一个事情
有主键,非主键字段依赖主键,ID字段就是主键,它能表示这一条数据是唯一的,其中“unique”表示唯一的、不允许重复的,确实它经常会修饰某个字段,保证该字段唯一性,然后再设置该字段为主键;
第三范式:非主独立
非主键列之间不能有依赖关系
非主键字段不能相互依赖,这个怎么理解呢,比如student表,班级编号受人员编号的影响,如果在这个表中再插入班级的班主任、数学老师等信息,你们觉得这样合适吗?肯定不合适,因为学生有多个,这样就会造成班级有多个,那么每个班级的班主任、数学老师都会出现多条数据,而我们理想中的效果应该是一条班级信息对应不同的任课老师,这样更易于我们理解,这样就形成class表,那么student表和class表和teacher表中间靠哪个字段来关联呢,肯定是通过class表中的"studentNo和"teacherNo"对其进行关联,这个字段也叫做两个表的外键;
事务
MySQL 的四种隔离级别
- Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
- Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是 MySQL 默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓 的 不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的 commit,所以同一 select 可能返回不同结果。
- Repeatable Read(可重读)
这是 MySQL 的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。
- Serializable(可串行化)
通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
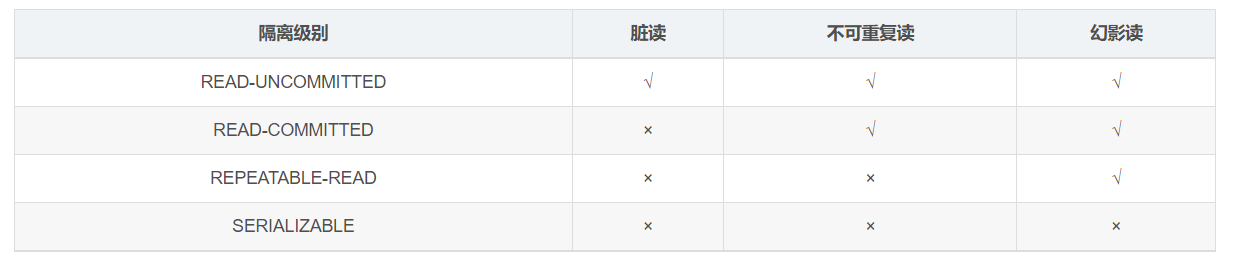
- 脏读:事务 A 读取了事务 B 更新的数据,然后 B 回滚操作,那么 A 读取到的数据是脏数据
- 不可重复读:事务 A 多次读取同一数据,事务 B 在事务 A 多次读取的过程中,对数据作了更新并提交,导致事务 A 多次读取同一数据时,结果 不一致。
- 幻读:系统管理员 A 将数据库中所有学生的成绩从具体分数改为 ABCDE 等级,但是系统管理员 B 就在这个时候插入了一条具体分数的记录,当系统管理员 A 改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
日志类型
REDO LOG
重做日志 ,提供再写入操作,恢复提交事务修改的页操作,用来保证事务的持久性。
- 先将原始数据从磁盘中读入内存中来,修改数据的内存拷贝
- 生成一条重做日志并写入redo log buffer,记录的是数据被修改后的值
- 当事务commit时,将redo log buffer中的内容刷新到 redo log file,对 redo log file采用追加 写的方式
- 定期将内存中修改的数据刷新到磁盘中
UNDO LOG
回滚日志 ,回滚行记录到某个特定版本,用来保证事务的原子性、一致性。
在 MySQL innodb 存储引擎中用来实现多版本并发控制,这个方法叫做MVCC,本质是乐观锁的实现
- 每个事务只会使用一个回滚段,一个回滚段在同一时刻可能会服务于多个事务。
- 当一个事务开始的时候,会制定一个回滚段,在事务进行的过程中,当数据被修改时,原始的数据会被复制到回滚段。
- 在回滚段中,事务会不断填充盘区,直到事务结束或所有的空间被用完。如果当前的盘区不够用,事务会在段中请求扩展下一个盘区,如果所有已分配的盘区都被用完,事务会覆盖最初的盘 区或者在回滚段允许的情况下扩展新的盘区来使用。
- 回滚段存在于undo表空间中,在数据库中可以存在多个undo表空间,但同一时刻只能使用一个 undo表空间。
- 当事务提交时,InnoDB存储引擎会做以下两件事情: 将undo log放入列表中,以供之后的purge操作 判断undo log所在的页是否可以重用,若可以分配给下个事务使用
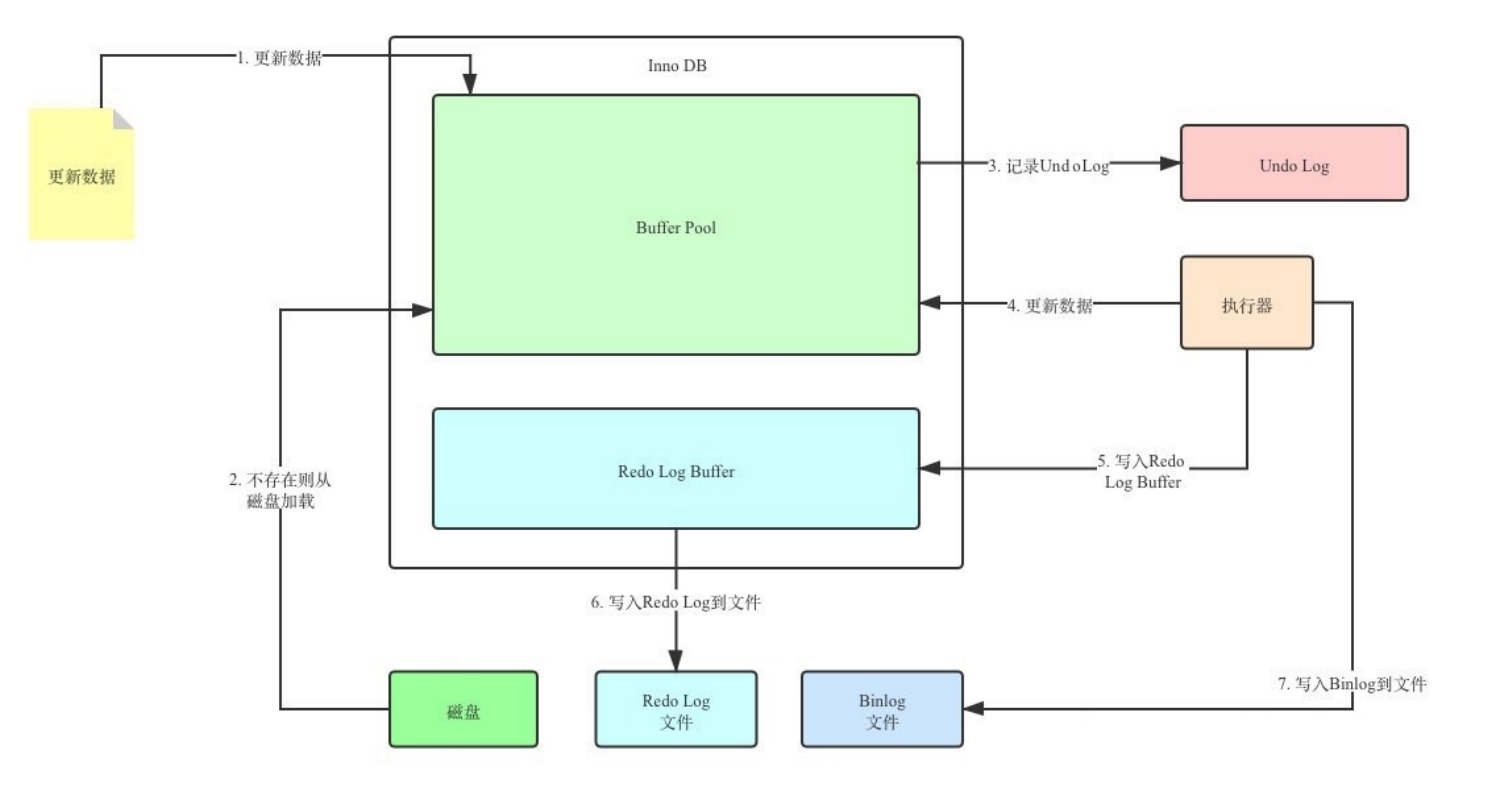
- binlog:记录所有数据库表结构变更(例如 CREATE、ALTER TABLE)以及表数据修改(INSERT、UPDATE、DELETE)的二进制日志。
MVCC
- MVCC 的实现依赖于:隐藏字段、Undo Log、Read View
- InnoDB 每一行数据都有一个隐藏的回滚指针,用于指向该行修改前的最后一个历史版本,这个历史版本存放在 undo log 中。如果要执行更新操作,会将原记录放入 undo log 中,并通过隐藏的回滚指针指向 undo log 中的原记录。其它事务此时需要查询时,就是查询 undo log 中这行数据的最后一个历史版本。
- MVCC 最大的好处是读不加锁,读写不冲突,极大地增加了 MySQL 的并发性。通过 MVCC,保证了事务 ACID 中的 I(隔离性)特性
锁
需要注意的是对于 InnoDB 引擎来说,读锁和写锁可以加在表上,也可以加在行上。
- 读锁 :也称为 共享锁 、英文用 S 表示。针对同一份数据,多个事务的读操作可以同时进行而不会 互相影响,相互不阻塞的。
- 写锁 :也称为 排他锁 、英文用 X 表示。当前写操作没有完成前,它会阻断其他写锁和读锁。这样 就能确保在给定的时间里,只有一个事务能执行写入,并防止其他用户读取正在写入的同一资源。
表锁。开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
行锁。开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
在MySQL中只有InnoDB存储引擎可以使用行锁。
lock table有如下两种表达方式:
- lock table xxx read,只读方式锁住xxx,该表只能被select,不能被修改。如果在lock时,该表上存在事务,则lock语句挂起,直到事务结束。多个会话可以同时对表执行该操作。
- lock table xxx write,读写方式锁住xxx,lock table的会话可以对表xxx做修改及查询等操作,而其他会话不能对该表做任何操作,包括select也要被阻塞。
可以同时锁住多个表。
隔离级别与锁的关系
在Read Uncommitted级别下,读取数据不需要加共享锁,这样就不会跟被修改的数据上的排他锁冲突
在Read Committed级别下,读操作需要加共享锁,但是在语句执行完以后释放共享锁;
在Repeatable Read级别下,读操作需要加共享锁,但是在事务提交之前并不释放共享锁,也就是必须等待事务执行完毕以后才释放共享锁。
SERIALIZABLE 是限制性最强的隔离级别,因为该级别锁定整个范围的键,并一直持有锁,直到事务完成。
一些函数笔记
1.计算日期差
datediff(a.日期, b.日期) = 1 #a比b大一天2.四舍五入
select round(1123.26723,2); #保留两位小数